

Cluster Raspberry Pi od Zera
Inspiracją tego przedsięwzięcia był NetworkChuck, który nagrał świetny materiał na temat zbudowania własnego lokalnego klastra kubernetes na platformie Raspberry Pi. To będzie dość długi artykuł. Przedstawię w nim moje przemyślenia odnośnie montażu, jak i przygotowania samych OS-ów na Raspberry.
My zrobimy to nieco inaczej. Wykorzystamy podejście IaC (Infrastructure as Code) do zdeployowania K3s na Raspberry Pi. Przy okazji opiszę problemy, na które trzeba zwrócić uwagę podczas wstępnej konfiguracji systemu na Raspberry. Nie zostały one omówione w materiale u Chucka, ponieważ mogły nie występować w czasie, kiedy on to robił..
Architektura
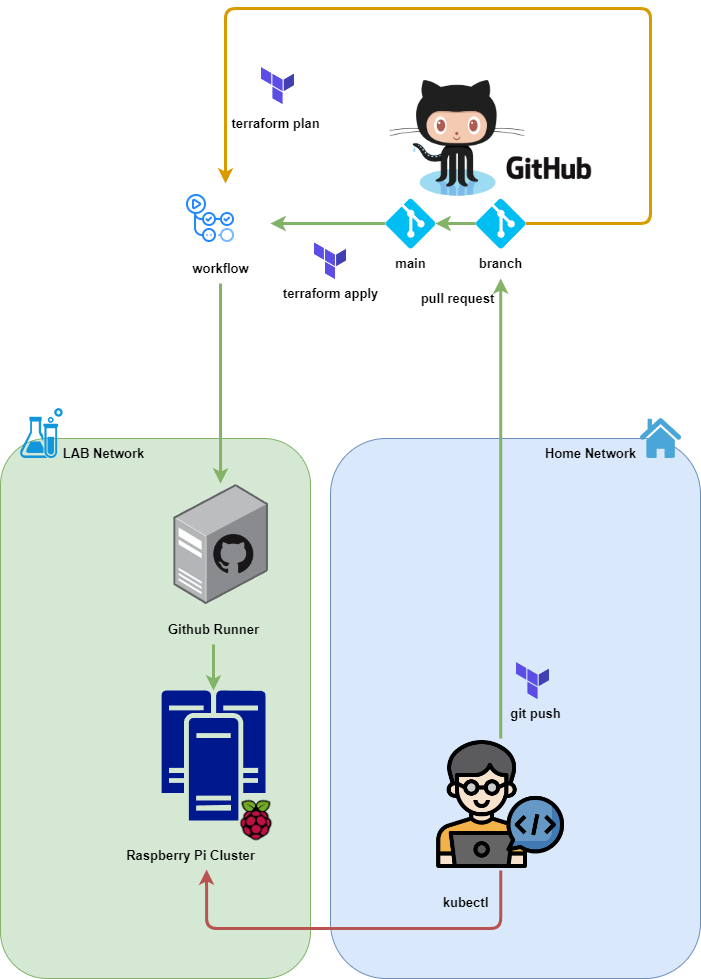
Architektura nie różni się znacząco od tej, która została opisana w poprzednim artykule na temat wdrażania K3S z pomocą Github Actions. Główną różnicą w implementacji jest wykreowanie odrębnej podsieci na potrzeby całego laba. Nie jest to konieczność, ale warto (o ile mamy taką możliwość) wykreować odrębną podsieć, która będzie działała na nieco innych zasadach niż regularna sieć domowa. Dzięki temu będzie można bardziej swobodnie wprowadzać różne zmiany bez wpływu na działanie pozostałych urządzeń.
Krok pierwszy: Hardware
Do montażu płytek Raspberry wykorzystałem dedykowaną obudowę rack: PI-CLUSTER-CASE. Obudowa jest w stanie pomieścić osiem modułów Raspberry. Bardzo fajnym dodatkiem, będącym częścią zestawu jest specjalny adapter koloru czarnego, widoczny na pierwszym zdjęciu. Wkłada się go w port karty microSD, umożliwia dostęp do portu, który jest umieszczony pod płytką. Po zamontowaniu płytki w racku było by to praktycznie niemożliwe.
Dwa duże wiatraki – biorąc pod uwagę prędkość z jaką się krącą, pracują całkiem cicho. Podświetlenie RGB nadaje całej konstrukcji gamingowego charakteru.
Najtrudniejszym elementem montażu było dopasowanie drugiej ścianki mini-racka. Wymaga to nieco wprawy. Wykonanie konstrukcji oceniam bardzo dobrze. Wszystkie otwory są idealnie spasowane, każda wypustka, czy otwór na śrubkę był we właściwym miejscu.








Dalej opisane kroki powtarzamy dla każdego modułu Raspberry, jaki przeznaczyliśmy na budowę clustra.
Krok drugi: Instalacja systemu
Instalację systemu przeprowadziłem w trybie „headless” – czyli bez podłączania monitora do Raspberry. Do wykonania instalacji jest potrzebna przejściówka microSD na USB, którą możemy podłączyć do PC na którym przygotujemy system.
Instalację systemu operacyjnego zaczynamy od pobrania i zainstalowania programu: Raspberry Pi Imager. Program dostępny jest na platformy: Windows, MacOS oraz Linux (Ubuntu).
Wgranie systemu na kartę microSD
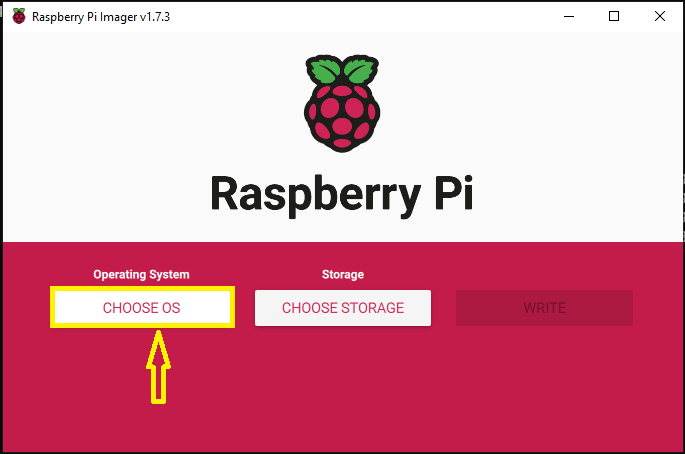
Zaczynamy od kroku CHOOSE OS
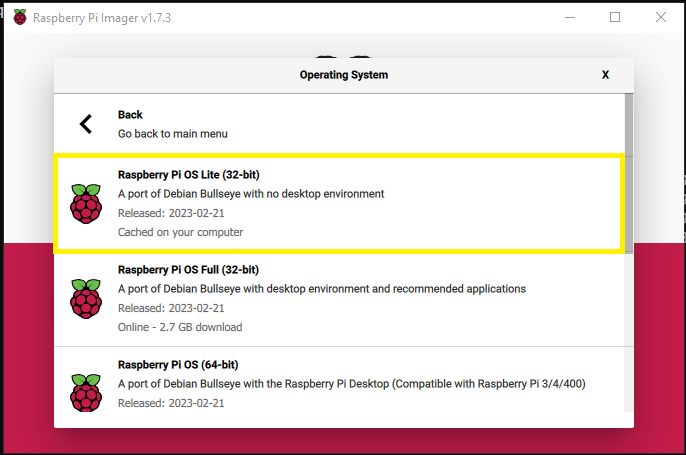
Raspberry Pi OS (other) -> Raspberry Pi OS Lite (32-bit)
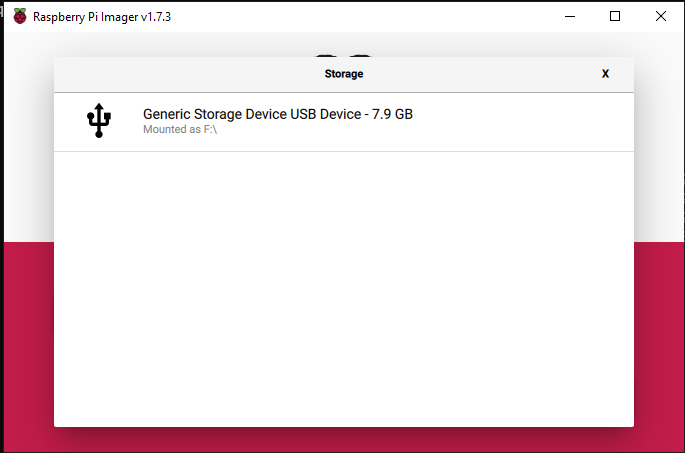
Choose Storage
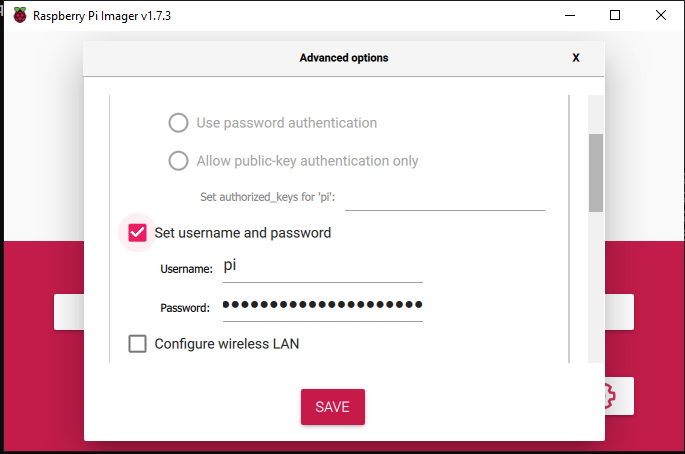
Bardzo ważny krok. Na głównym ekranie znajduje się ikona dodatkowych ustawień. Za jej pomocą należy ustawić login oraz hasło jakie ma zostać utworzone na etapie instalacji na naszym Raspberry. Bez tego kroku nie będzie możliwości zalogowania się przez ssh.
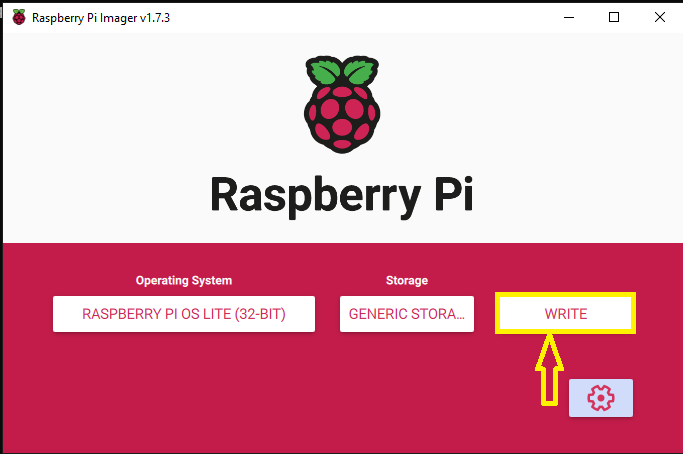
Ostatni krok: instalacja systemu na karcie microSD.
Wkładamy z powrotem karty pamięci do Raspberry i czekamy ok. 2 min. na zbootowanie się systemu.
Krok trzeci: Pierwsze bootowanie systemu (wstępna konfiguracja)
Wykonanie czynności, które zaraz opiszę, nie zadziałały tak jak opisał to Chuck u siebie. Aczkolwiek wystarczyły do tego, aby połączyć się do systemu przez ssh.
Co zadziałało

- Udało się skonfigurować statyczny adres IP
- uruchomił się sshd
Co nie zadziałało

- Brakowało bramy domyślnej
- nie ustawił się hostname
Po chwili wyłączamy Raspberry i z powrotem podłączamy kolejno karty pamięci w komputerze. Po ich podłączeniu pojawi się dysk o nazwie boot. Jest on widoczny w Windowsie pod następną dostępną literą dysku. Musimy przeedytować dwa pliki. Pierwszym z nich jest cmdline.txt. Do końca linijki tego pliku doklejamy taki fragment:
cgroup_memory=1 cgroup_enable=memory ip=10.1.1.10::10.1.1.1:255.255.255.0:k3s-master:eth0:offW części związanej z konfiguracją IP, pierwszy adres zostanie nadany naszemu modułowi Raspberry, kolejny to adres IP lokalnego gatewaya, maska podsieci oraz hostname (k3-master). Opcja eth0:off ustawia nazwę interfejsu sieciowego jako eth0 i wyłącza konfigurację przy użyciu DHCP.
Dodatkowo należy zmodyfikować plik config.txt i na jego końcu dodać opcję: arm_64bit=1 Uruchamia ona kernel Raspbiana w wersji 64 bitowej.
Aktywacja ssh
Aby sshd uruchamiało się wraz z systemem należy na dysku boot utworzyć pusty plik o nazwie: ssh
- Windows: New-Item ssh
- Linux/Mac: touch ssh
Krok czwarty: Logowanie się na raspberry i ostatnie poprawki
Tak, jak wspomniałem wcześniej, musiałem nieco poprawić konfigurację systemu. Należy to wykonać na każdym Raspberry, które będzie używane w clustrze.
Ustawienie bramy domyślnej
Aby to zrobić w sposób tymczasowy trzeba wykonać polecenie
route add default gw 10.1.1.1Na tym etapie można zainstalować już jakieś oprogramowanie, np. edytor vim. Permanentną konfigurację IP wykonuje się w pliku: /etc/dhcpcd.conf.
interface eth0
static ip_address=10.1.1.10/24
static routers=10.1.1.1
static domain_name_servers=10.1.1.1 8.8.8.8Hostname
Hostname należy zmienić w dwóch plikach: /etc/hostname oraz poprawić /etc/hosts.
127.0.1.1 k3s-masterPo restarcie systemu, będziemy mieli prawidłowo skonfigurowany OS pod cluster, który zostanie na niego zdeployowany.
Krok piąty: Tworzymy IaC w Terraformie
W artykule na temat konfiguracji Github Actions opisałem, jak stworzyć workflow oraz zainstalować self-hosted runnera. W dalszej części artykułu zrobię przegląd kodu terraforma, który ma za zadanie skonfigurować cluster k3s. Jeśli chodzi o implementację rozwiązania, nie różni się ona od tego, co wcześniej robiłem na VirtualBoxie.
W związku z tym, że instalacja K3S nie jest złożonym procesem – wymaga uruchomienia jednego lub dwóch (w przypadku mastera) poleceń, zdecydowałem się zamknąć całość w dwóch plikach. Nie licząc definicji main oraz zmiennych użytych w projekcie, które są wspólne i które umieściłem w oddzielnych plikach.
Cały projekt opublikowałem w repozytorium: https://github.com/kkrolikowski/homelab-tf Zawartość konfiguracji, która się tam znajduje można użyć i dostosować do własnych celów.
main.tf
W tym pliku zdefiniowane są dwie kwestie: lista wymaganych providerów, które udostępniają nam metody pozwalające na wykonywanie akcji na infrastrukturze oraz backend, który jest miejscem przechowywania pliku terraform.tfstate. Plik tfstate jest bardzo ważny z punktu widzenia terraforma. Zapisany jest w nim stan wdrożonej konfiguracji. Bez tego pliku terraform nie jest w stanie określić co zostało wdrożone a co nie.
null = {
source = "hashicorp/null"
version = "3.2.1"
}null provider udostępnia resource null_resource, który jest potrzebny do wykonania połączenia ssh z modułami raspberry
external = {
source = "hashicorp/external"
version = "2.2.3"
}external provider udostępnia typ danych (data type) o tej samej nazwie, który umożliwia wykonanie zdalnie kodu i przechwycenie outputu.
backend "local" {
path = "/home/ubuntu/terraform/terraform.tfstate"
}backend definiuje miejsce przechowywania pliku tfstate
variables.tf
variable "master_node" {
description = "K3S Master Node"
type = string
default = "1.1.1.1"
}
variable "worker_nodes" {
description = "List of K3s worker nodes"
type = list(any)
default = ["2.2.2.2"]
}
variable "vm_user" {
description = "Generic VM login"
type = string
default = "generic"
}
variable "vm_pass" {
description = "Generic VM user password"
type = string
default = "secret"
}W tym pliku zdefiniowane są wszystkie zmienne użyte w projekcie wraz z ich domyślnymi wartościami. Podczas implementacji można oczywiście wprowadzać własne – docelowe dane do tego pliku, ale wygodniejszym rozwiązaniem jest użycie pliku tfvars. Dzięki niemu możemy w prosty sposób rozdzielić konfigurację środowiska produkcyjnego od testowego.
Zmienna worker_nodes jest tablicą (list), ponieważ w miarę rozbudowy clustra i dołączania do niego kolejnych nodów, będzie trzeba ją aktualizować i dodawać następne elementy. Z tej zmiennej korzysta iterator, który wykonuje deployment na każdym z elementów ze zdefiniowanej w nim listy.
k3s-deploy-master-node.tf
W pliku zdefiniowane są trzy odrębne obiekty: resource, data oraz output.
resource "null_resource" "k3s_master_node" {
connection {
type = "ssh"
host = var.master_node
user = var.vm_user
password = var.vm_pass
}
provisioner "remote-exec" {
inline = [
"echo ${var.vm_pass} | sudo -S date",
"curl -sfL https://get.k3s.io | sh -"
]
}
}Resource o nazwie k3s_master_node posiada zdefiniowane dwa bloki: connection oraz provisioner. Connection opisuje jak terraform ma wykonać połączenie a provisioner – w tym przypadku: remote-exec wykonuje polecenia na systemie opisanym w connection.
W tym miejscu zastosowałem mały „hack”. „curl -sfL https://get.k3s.io | sh –” w sposób niejawny uruchamia sudo, które z kolei wymaga podania hasła. Wykorzystując właściwość sudo, które na pewien czas zapamiętuje hasło, podane przy pierwszym poleceniu, uruchamiam sudo -S date przekazując hasło w potoku. W ten sposób drugie polecenie (curl) nie wymaga już podania hasła w sposób interaktywny.
data "external" "k3s_master_token" {
depends_on = [
null_resource.k3s_master_node
]
program = ["/bin/bash", "-c", "echo \"{\\\"token\\\":\\\"$(sshpass -p ${var.vm_pass} ssh -o StrictHostKeyChecking=no ${var.vm_user}@${var.master_node} \"echo ${var.vm_pass} | sudo -S cat /var/lib/rancher/k3s/server/node-token\")\\\"}\""]
}external data o nazwie k3s_master_token ma za zadanie odczytać z pliku /var/lib/rancher/k3s/server/node-token token mastera. Jest on potrzebny do rejestracji kolejnych nodów clustra kubernetes. Dane wynikowe muszą być zwrócone przez program w formacie JSON. W tym przypadku polecenie zwraca prosty obiekt:
{ "token": "zawartośćplikunode-token" }Dane zwrócone przez ten data source będą dostępne w kluczu: data.external.k3s_master_token.result.token
k3s-deploy-worker-nodes.tf
Plik k3s-deploy-worker-nodes.tf jest podobny do tego, który opisuje mastera. Omówię więc główne różnice.
depends_on = [
data.external.k3s_master_token
]Nie możemy wdrożyć worker-nodów, jeśli nie uruchomi się master-node. Tylko master posiada token, który jest potrzebny do podłączenia workerów.
for_each = toset(var.worker_nodes)
connection {
type = "ssh"
host = each.key
user = var.vm_user
password = var.vm_pass
}Za pomocą iteratora for_each terraform odczytuje każdy element listy worker_nodes i wykonuje zdefiniowany blok resource. Wartość (w przypadku listy) elementu jest dostępna w kluczu: each.key.
provisioner "remote-exec" {
inline = [
"echo ${var.vm_pass} | sudo -S date",
"curl -sfL https://get.k3s.io | K3S_URL=https://${var.master_node}:6443 K3S_TOKEN=${data.external.k3s_master_token.result.token} sh -"
]
}remote-exec różni się jedynie poleceniem curl. Aby podłączyć worker-node do mastera należy w potoku ustawić dodatkowe zmienne: K3S_URL oraz K3S_TOKEN.
Uruchomienie wdrożenia
Automatyczne
Jeśli korzystamy z Github Actions, wystarczy wdrożyć w repozytorium kod i wykonując a następnie mergując pull-requesta wszystko wdraża się automatycznie na raspberry.
Ręczne
terraform init
terraform plan -var-file="/home/ubuntu/k3s/k3s.tfvars"
terraform apply -auto-approve -var-file="/home/ubuntu/k3s/k3s.tfvars"Zdalne połączenie do K3S
Podobnie jak w w przypadku innych implementacji kubernetes istnieje możliwość konfiguracji kubectl na lokalnej stacji roboczej aby zdalnie deployować aplikacje na clustrze.
Cała konfiguracja znajduje się pliku: /etc/rancher/k3s/k3s.yaml na masterze. Jeśli nie mamy zdefiniowanej żadnej konfiguracji kubernetes na komputerze, wystarczy zawartość tego pliku zapisać lokalnie w ścieżce: ~/.kube/config W przeciwnym razie konfigurację trzba blok po bloku wstawić w odpowiednie miejsca do istniejącego pliku.
Po zapisaniu konfiguracji można sprawdzić połączenie do clustra.
kubectl get all --all-namespaces
# Przełączenie kontekstu
kubectl config use-context [nazwa kontekstu k3s z pliku]